

With every mega scale web company talking about their spine-leaf fabric designs it sounds as if everyone who is building a Data Center switch fabric needs and is going to implement one. Is that really the case though?
In this blog post we will look at whether spine-leaf designs are always better than large chassis based Data Center switch fabric designs. We will touch on some important factors to consider when choosing between which fabric design to implement. Next I will provide a simple example for comparison that will better illustrate why several of these factors are critically important.
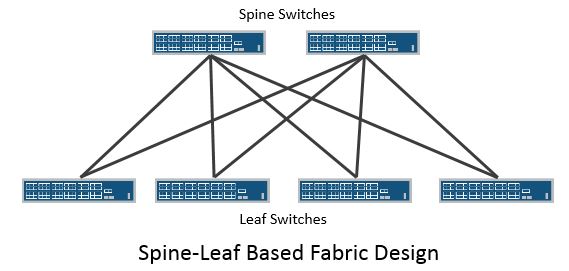
First off let’s start with what a spine-leaf fabric actually is. It’s a physical topology design where endpoints connect to leaf switches and all leaf switches connect to a spine switch layer. Every leaf connects via an uplink port to each of the spines. The spines don’t connect to each other, just to the leaf switches. This physical topology design results in every endpoint being an equidistant number of hops away from every other endpoint with consistent latency. There are effectively 3 stages in this design where there is an ingress leaf stage a middle stage via the spine and an egress leaf stage. This design is sometimes referred to as a Clos fabric, after Charles Clos who created this design back in 1952 in order to scale a network larger than the radix of the largest telephone switch that was available at the time. This design being rooted in the need to scale past the largest available switching component will be a key factor we consider later in this post when comparing a large chassis based design to a spine-leaf design. A spine-leaf topology can be utilized for a layer 2 or a layer 3 fabric. It is most often coupled with an L3 design, commonly referred to as an ‘IP Fabric’, where routing is employed on all of the interconnection links between the leaf and spine switches. Every endpoint connected to a leaf switch is reachable via N # of equidistant ECMP paths where N is the # of spine switches in use. In the layer 3 “IP Fabric” paradigm the result is effectively a distributed control plane.
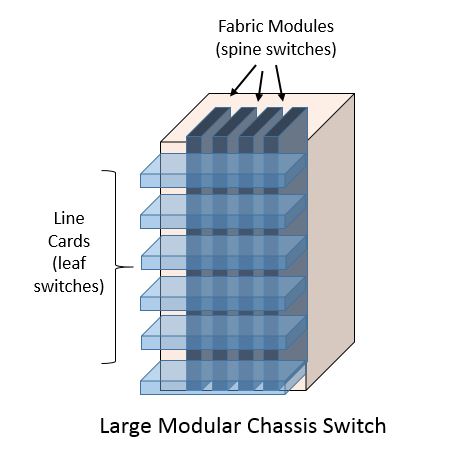
In contrast a large modern chassis based switch is actually a Clos fabric enclosed in a single piece of sheet metal with a shared control plane, power and cooling subsystem. The line cards act like leaf switches and the fabric modules act like spine switches. The fabric links that interconnect all of the line cards (leafs) are internal to the switch fabric modules (spine) and don’t require a conventional routing protocol between them as there is a single control plane in the chassis based system which updates the forwarding tables on the line cards.
Note: Its worth mentioning that there is technically a hybrid model of the single control plane chassis based switch and the distributed control plane spine-leaf fabric. An Open Compute Platform (OCP) design called “Backpack”, submitted by Facebook, now exists for a 4-slot chassis comprised of 32x100GE line cards and integrated fabric modules. The difference in this design is that each component inside the shared chassis is a separate switch from a control plane and management plane standpoint. This basically acts like a Clos fabric in a box whereby the fabric cards act as discrete spine switches and the line cards act as discrete leaf switches running routing protocols between each other. So while the packaging looks like an integrated modular chassis design its really comprised of a dozen individually managed components. Facebook is actually using tens (if not hundreds) of these 4-slot chassis together as a building block in a massive spine-leaf fabric design. This means lots of individual devices to manage and monitor. The major benefit to this approach is improved cable management as fabric interconnects between spine and leaf are internal to the 4-slot chassis as well as better cooling.
Now that we have a better understanding of what a spine-leaf fabric is let’s look at the big picture view. What are the actual business requirements that you are building a Data Center network towards? Are you building your network according to the requirements of an application that you are developing or are you building it to run “anything” that might get thrown at it? The former is the case when you look at companies like Facebook or LinkedIn that seek to make the network technology interface with the business better. The latter occurs when you are building an Infrastructure as a Service (IaaS) Data Center fabric that will host someone else’s applications. Is the application designed with scale out and fault tolerance built in, or is it expected that the network will deliver this on its behalf? You need to know the requirements and behavior of the application. Is ultra-low latency required? Is packet loss tolerated? Is every end host consistently using all of its available bandwidth or is the traffic pattern less deterministic?
How big does your Data Center fabric need to be? Don’t just assume that you need to do a spine-leaf design because that’s what all the massive scale players are doing. The key here is ‘massive scale’. These companies have unique problems to solve at the largest known scale in the industry. You need to be realistic here and ask yourself is your Data Center network actually going to need to scale as large as a Google, Facebook or LinkedIn? If you are only talking about 2,000 servers versus 20,000 to upwards of 100,000 then you are building a very different network then the massive scale players in the industry.
What tech is in your network team’s wheelhouse? Are they comfortable with a routing protocol like BGP and proficient with configuration automation and telemetry collection tools required to deploy and monitor a very large scale Data Center fabric compromised of tens if not hundreds of individual network devices?
Another interesting concern is whether or not you intend to pursue a disaggregated software and hardware strategy whereby the switch Network OS (NOS) and the switch HW come from different vendors as opposed to the traditional ‘vertically integrated’ model of SW and HW coming from the same vendor. This is important to know up front as there currently appears to be far less options for switch NOS’s that will run a large chassis based switch versus the smaller 1 or 2RU Top-of-Rack (TOR) switches. At the time of this writing the only OCP submitted designs for a large chassis based switch are the Edgecore Networks OMP 256 and 512 models. What this inevitably means is that a 1/2RU open networking switch will give you much a greater choice of Switch NOS and Switch Hardware options.
If you decide to go with a large chassis based switch from a traditional ‘vertically integrated’ network vendor you are likely going to stay with that network vendor for 5-7 years and upgrade the line cards in the switch chassis to go to the next highest interface speed and density cards when needed. With the spine-leaf design everything is a distributed line card and you replace the individual switches with another switching silicon generation of 1RU switches when needed. At this point, given the broader choices in the open ecosystem in the smaller 1 or 2RU fixed switches space, you can elect to change out the hardware or software vendor.
| Consideration | Large Chassis Switch Pair | Spine-Leaf “IP Fabric” |
| Fabric Construct | Fabric links between line cards are internal to the chassis. Usually proprietary, hard to debug w/out vendor TAC, hard to see what is really going on | Fabric is composed of external links between switches running standards based protocols. Easy to monitor and understand what’s happening on the links using a well-established troubleshooting methodology. |
| Failure Domain | Large fault domain here. Losing an entire switch means losing ½ your fabric bandwidth. For SW upgrades you really need mechanisms like NSR and ISSU to work reliably else you will have long reboot times. | Small failure domain. Individual switches can fail or be upgraded separately to reduce impact. Shorter reboot times as we are dealing with individual switches |
| Rack Units (RU) and power | Chassis based switches will consume some extra rack units and power for routing engines and other shared system components. | How many rack units and power consumed will largely depend on how much oversubscription is acceptable for your application as increasing fabric bandwidth involves adding more spine switches (which means more optics and cabling as well) |
| Optics/Cabling | Chassis design will use less optics and cabling due to the fabric interconnection links being internal to the chassis | S/L requires optics and cables for constructing the external fabric interconnections between switches |
| Config Management | Only 2 devices to manage as long as we are building to less than 2,000 server facing ports | 10’s of devices to manage. Need to implement a config automation tool/process. Uses more IP addresses for P2P links between switches. Needs a routing protocol configured as the distributed control plane of the fabric |
| Oversubscription | In a typical chassis based switch there should be no oversubscription | The acceptable level of oversubscription is key to number of overall spine switches, fabric links, optics/cables, IP addresses, rack units and power |
| Packet Buffers | Custom ASIC based chassis switches typically have deep buffers (GB), though there are some that leverage merchant silicon with shallow buffers (MB). | 1 and 2RU merchant silicon switches typically come with shallow buffers (MB) though there are some exceptions here as well |
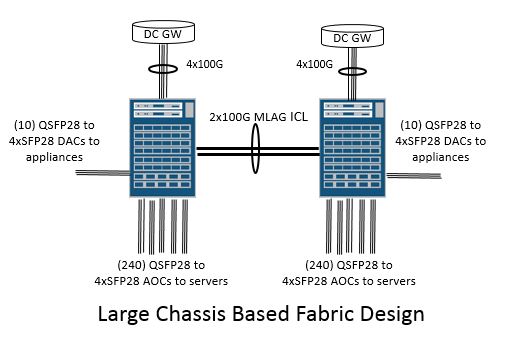
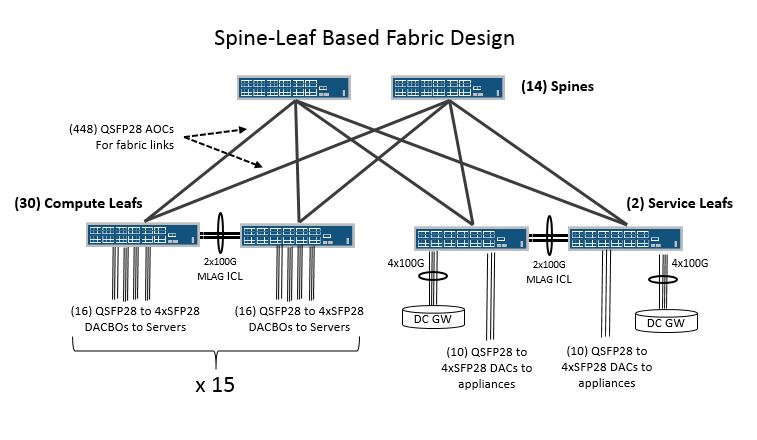
Let’s take a look at how some of these factors listed above combine to play out in a simplified example. In this case I’m simply going to determine the maximum amount of dual-homed servers with 25G NICs that can be supported in a large chassis based system and then attempt to build a spine-leaf fabric design with the same level of reach and oversubscription. For this example I’ve decided to compare a large 8-slot chassis fabric based on Broadcom Tomahawk merchant silicon with a spine-leaf fabric of 1RU switches based on the same merchant silicon switching ASIC to make this as much of an ‘apples to apples’ comparison as possible since each 1RU switch is equivalent to a line card or fabric module in the chassis based system. I’ve reserved a reasonable amount of ports in each fabric design to account for exit links towards the DC Edge Routers and some physical appliances like Firewalls, anti-DDOS, Monitoring Probes and other devices that may need to exist in the Data Center. The legacy hosted applications in this DC are not distributed fault-tolerant applications and therefore will require active/active 25G LAG connections to the switches for providing higher availability.
| Consideration | Large Chassis Switch Pair | Spine-Leaf “IP Fabric” | ||||
| Switch Hardware | (2) 8-slot chassis w/32x100G line cards | (46) Total 1RU 32x100G switches
•(30) 1RU compute leafs •(2) 1RU service leafs (host DC GW/PNFs •(14) 1RU spine switches |
||||
| Total Rack Units | 26RU | 46RU | ||||
| Total (Max) Power | 12KW | 17.5KW | ||||
| Hardware location | Middle-of-row (MOR) in network cabinet | Leaf in Top-of-Rack (TOR) in server cabinets and MOR network cabinet for spine switches | ||||
| Number of dual-homed 25G servers | 960 (30 server racks of 32 servers) | 960 (30 server racks of 32 servers) | ||||
| Oversubscription | None | ~1.2:1 | ||||
| Total non-server ports (to DC GW/MLAG ICLs/Appliances/Free ports) | 8x100G/4x100G/10x100G/0 | 8x100G/64x100G/10x100G/18x100G | ||||
| Cabling
This example utilized combinations of Active Optical Cables (AOC), Direct Attach Copper (DAC) and Direct Attach Copper Break Out Cables (DACBO) |
(480) QSFP28 to 4xSFP28 AOCs to the servers
(480) + (8 to DC GW + 2 DACs for MLAG Inter-Chassis-Links (ICLs) + 10x QSFP28 to 4xSFP28 DAC for Appliances) = 500 physical cables |
(448) QSFP28 AOCs from middle of row spines to leafs in the top of rack
Leaf to servers via (16) QSFP28 to 4xSFP28 DACBO per leaf per rack (448) for 100GE fabric links + (16) QSFP28 to 4xSFP28 DACBO per leaf to the servers x 30 racks = 928 + (8 to DC GW + 32 DACs for MLAG ICLs +10 for appliances) = 978 physical cables |
||||
| Optics | 8 to DC GW = 8 (100G QSFP28 SR4)
* QSFP28 to 4xSFP28 AOC and DAC cables means no 25G optics on the servers, appliances or MLAG ICLs |
8 to DC GW = 8 (100G QSFP28 SR4)
* QSFP28 DAC and QSFP28 to 4xSFP28 DACBO means no 25G optics on the servers, appliances or MLAG ICLs |
||||
| Total addressable links (IPv4 addresses) | 30 IRBs + 2 for MLAG ICL + 2 for LAGs to DC GW + 40 for PNFs = 74 | 896 (p2p fabric links) + 32 for MLAG ICLs + 2 for LAGs to DC GW + 40 for PNFs = 970 | ||||
There are some interesting observations that can quickly be made here.
- First to get to nearly the same level of oversubscription with the spine-leaf fabric design I need to consume 20 more Rack Units and 5.5 KW more power. Most of this is attributable to the need to have physical links between the spine and leaf switches which consume (16) 100GE ports on the leaf switches that are not required to be used on the line cards inside of a chassis based switch as those connections are internal to the switch fabric in the chassis. The ‘external switch fabric’ of the spine-leaf design requires (14) rack units worth of spine switches to deliver the same function as the fabric modules which are internal to the chassis based system.
- The requirement to dual-home the 25G NICs on the servers to a pair of switches via LAG requires burning 2 additional interfaces between each pair of leaf switches for running the MLAG/MC-LAG inter-chassis links. In the chassis based switch this only requires a single pair of links for running the MLAG/MC-LAG ICL between the two chassis. Also important to note here is that MLAG/MC-LAG only works between a pair of switches. So when you connect the servers directly to a pair of large chassis based switches you have already confined the limit of how big the fabric can be to 2 switches.
- The total number of IP addressing required to build the spine-leaf design is significantly higher primarily due to the need to address all of the P2P links that comprise the physical fabric links between the leaf and spine switches.
Another interesting observation was that the choice of location of the switches and the type of cabling in use can make a huge difference in the amount of cables and type and cost of the optics required. There are several different permutations here that could have been chosen and the decision tree for where to place the switches and how to run the cabling warrants its own blog post. The use of Direct Attach Copper (DAC), Active Optical cables (AOC) and Direct Attach Copper Break-Out (DACBO) cables created a large reduction in the 100G optics required. I think it’s safe to say that an optimum rack placement and cabling solution can be found for either the chassis based fabric design or spine-leaf fabric design, such that neither fabric design solution should have a tremendous advantage or disadvantage here.
Conclusion:
If you can handle having a potentially very large failure domain, then a traditional large chassis based system can be a convenient option for deploying a non-blocking switch fabric POD of less than 2,000 ports (1,000 dual-homed servers). It requires less devices to provide configuration management and monitoring for, less physical cabling, doesn’t need a routing protocol running between elements to bootstrap the fabric and consumes less IP addressing.
However, if one intends to extend the Data Center fabric to 3 to 5 times this size then N more large chassis based systems would need to be deployed. What is also needed is another layer of chassis based switches introduced for interconnection between all of the PODs which would constitute a spine layer. What you now end up with in that case is a spine-leaf fabric constructed entirely of chassis based switches. The failure domain in this scenario now becomes incredibly important. If the spine layer that interconnects all of these PODs is a pair of 100G chassis based switches you can lose a large portion of bandwidth between any 2 PODs in your Data Center. The configuration management and monitoring advantages of the large chassis based system model also goes away in a Data Center of this size.
Disclaimer: The views expressed here are my own and do not necessarily reflect the views of my employer Juniper Networks