Do you find the dizzying array of optics form factors, connector types, cabling choices and device connectivity options in the Data Center difficult to consume and make sense of? In this particular segment we will look at some of the most popular types of Data Center optics and cabling options out there as well as examples of commerically available switching product platforms that leverage these. We will then cover the factors that influence when one might choose a specific type of optic and cabling for connecting end devices to these switches and wrap up with a table which summarizes what we have discussed.
When it comes to optics some important concepts to quickly knock off right out the gate are form factor, transceiver, connector type and cabling.
The form factor of an optic essentially defines the supported data transfer rate (speed) per lane, number of data transfer lanes, physical size and power characteristics of the optical transceiver.
Within each specific form factor there are multiple optical transceiver options which differ in the supported distance range and type of connectors and cabling they support.
You will see transceivers rated at specific distances when paired with a certain cabling type. Some example distance designations that commonly appear are SR (short-reach), IR (intermediate-reach) or LR (long-reach) which when combined with a supported cabling type will range from as few as 100m on Multi-mode fiber (MMF) for SR to upwards of 10km on Single-Mode Fiber (SMF) in the case of LR.
When it comes to cable types, Multi-mode fiber (MMF) cable is used in the Data Center for distances less than 400m. Single-Mode Fiber (SMF) cable is used for distances >400m where the connected end device is across the Data Center or for much longer distances like interconnects between Data Centers (DCI) that may span multiple kilometers. Cat6 and Cat7 copper cabling is still used for very short distance 1G and 10G connections.
In the Data Center the transceiver’s connector type is typically either an LC connector or an MPO/MTP connector. Duplex Single Mode Fiber (SMF) and Duplex Multi-Mode Fiber (MMF) cable types both support LC connectors while parrallel MMF trunks utilize MPO/MTP connectors. More on MPO/MTP below. RJ45 copper connector types for use with Cat6/7 cabling are also possible with some transceivers.


Figure 1: SFP transceiver (left) which accepts a cable with an LC connector (right)
MPO/MTP Connector
Multi-Fiber Push-On/Push-Off (MPO) is the standard and MTP is a brand of connector type. These connectors deal with handling the patching or termination of multiple parallel multi-mode fiber strands called ‘MTP trunks’. The most commonly seen type of parallel multi-mode fiber strand for interconnecting two devices is the 12-fiber MTP ‘trunk’ which consists of a length of 6-fiber pairs with MTP connectors on each end. In practice only 8 of the 12 fibers are actually used which is enough to provide 4 lanes of dual fibers. More efficient 8-fiber MTP trunks also now exist and are gaining in popularity. These MTP connectors commonly plug into either a QSFP+ 40G or QSFP28 100G form factor optical transceiver which both use 4 parallel data transfer lanes and are used for short length connections of <400m.


Figure 2: Male and Female (top) MTP connectors, MTP trunk Cable (bottom)
MTP harness connectors also exist which, for example, can take an 8-fiber MTP and break it out into 4xLC connectors. This would typically be used to breakout a 40G or 100G port on a switch to 4x10G or 4x25G endpoint connections respectively. This harness might plug directly into a switch port to breakout connections to a server in the same rack as the switch or used in conjunction with an in rack patch panel which provides connectivity to all the servers in rack.

Figure 3: 8-fiber MTP to 4 LC duplex harness
There are also versions of transceivers that have a cable directly pre-attached to them and therefore have no real connector. These Direct Attach Copper (DAC) or Active Optical Cables (AOC) are for very short distance connections in the range of 1 to 30m and are described in more detail further below.
Direct Attach Copper (DAC)
This is essentially a cable with the 10G SFP+, 40G QSFP+ or 100G QSFP28 transceivers pre-attached on both ends. These exist in either passive or active mode with passive having an effective distance of 1-5m while active can cover 5-10m of distance between the switch port and connected device. DAC is mostly used for in rack cabling when the switch and the connected device are in the same rack (Top-of-rack model). It is also possible to use an active DAC to extend the reach between a connected device to a middle of row or end of row switch location.
 Figure 4: DAC Cable
Figure 4: DAC Cable
Direct Attach Copper Break-Out (DACBO)
This functons just like the DAC above with the key difference being that the switch port end of the DAC will be have a 40G QSFP+ or 100G QSFP28 transceiver while the connected device end will have 4x10G SFP+ or 4x25G SFP28 connections available. These are typically used within a rack (TOR model).
 Figure 5:DAC Break-out Cable
Figure 5:DAC Break-out Cable
Active Optical Cables (AOC)
AOC are just like DAC in that the transceivers and the cable are a single fixed assembly. The key differences here are AOC being fiber which is thinner and more flexible with much longer effective reach in the 10 to 30m range allowing for them to be used in conjunction with middle and end of row switching device location designs. The drawback to using a really long AOC cable that runs from and end of row switch location to a device in a remote rack is that the entire cable assembly needs to be re-run in the event of a failure which may prove cumbersome. AOC’s also have breakout options for enabling 40G and 100G to breakout to 4x10G and 4x25G respectively. AOC’s are more expensive than DAC cables due to both active components and longer length cables.

Figure 6:Active Optical Cable

Figure 7: Active Optical Break-out Cable
Commonly used form factors
Next let’s look at the available type of optics form factors, how they have been historically used in DC switching gear as well as their performance, size, power and cost trend.
SFP+ – 10G Small Form Factor Pluggable Tranceivers
SFP+ is a single lane of 10Gbps which utilizes 1.5W of power. SFP+ transceivers can support RJ45 copper, LC fiber connectors or Direct Attach Copper (DAC) and Active Optical Cables (AOC). Typical 1RU switch configurations which leverage SFP+ have 48 SFP+ ports with 4 to 6 ports of QSFP+ 40G or QSFP28 100G for uplinks. 10G Data Center switches produced with SFP+ ports are now starting to give way to 25G switches with SFP28 ports and QSFP28 uplinks.

Figure 8: Juniper QFX5100-48s 1RU 48x10G SFP+ and 6x40G QSFP+ uplink Broadcom Trident 2 based switch
QSFP+ – Quad 10G Small Form Factor Pluggable Tranceivers
The QSFP+ is 4 lanes of 10Gbps which is slightly wider than an SFP+ and utilizes 3.5W of power. When comparted to SFP+ its 4x the bandwidth at roughtly 2.5x the amount of power consumed. QSFP+ transceivers will support LC fiber connectors, MPO/MTP connectors, Direct Attach Copper (DAC) and Active Optical Cables (AOC). It’s common to see 32 ports of QSFP+ on a 1RU ethernet switch and 36 QSFP+ ports on a modular chassis line card as this is typically the maximum amount of front panel real estate available for ports.

Figure 9: EdgeCore 1RU 32x40G QSFP+ Broadcom Trident 2 based switch
SFP28 – 25G Small Form Factor Pluggable Tranceivers
The SFP28 is a single lane of 28Gbits which is 25Gbps + error correction for an effective data rate of 25Gbps. SFP28 is the same size form factor as SFP+ so its 2.5 times the bandwidth of SFP+ in the same amount of space and at roughly the same price point. In addition, SFP28 is also backwards compatible with 10GE which allows for upgrading the DC switching infrastrucuture to support 25G without immediately having to also upgrade all of the devices that will plug into it _and_ allows for reuse of existing 2-pair MMF cabling. 1RU switching products have been introduced with 48x25G SFP28 densities with 4-6 additional ports supporting QSFP28 used as 100G uplinks.

Figure 10: DEll S5148F-ON 1RU 48x25G SFP28 and 6x100G QSFP28 uplink Cavium Xpliant based switch
QSFP28 – Quad 25G Small Form Factor Pluggable Tranceivers
The QSFP28 is 4 lanes of 28Gbits (25Gbps + error correction) providing either full 100Gbps operation or a break-out of (4) 25Gbps interfaces. Its important to note that the QSFP28 is the same size form factor and power draw as the QSFP+, yet provides 2.5x time bandwidth of QSFP+. Due to the same size form factor its possible to see switching equipment flexibly support the use of either QSFP+ or QSFP28 pluggable optics in the same port(s). Most 1RU switches will have 32xQSFP28 ports which will support break out QSFP28 to 4x25G. Modular switch chassis will sport line cards that leverage between 32 and 36 ports supporting QSFP28. QSFP28 is also popular as a 100G uplink port in newer 48x25G 1RU switches.
 Figure 11: Dell Z9100-ON 1RU Broadcom Tomahawk based switch with 32x100G QSFP28 ports
Figure 11: Dell Z9100-ON 1RU Broadcom Tomahawk based switch with 32x100G QSFP28 ports
Device placement in the Data Center
Another key concept to understand is the typical switch device placement locations in the Data Center
Top-of-Rack (TOR) Designs
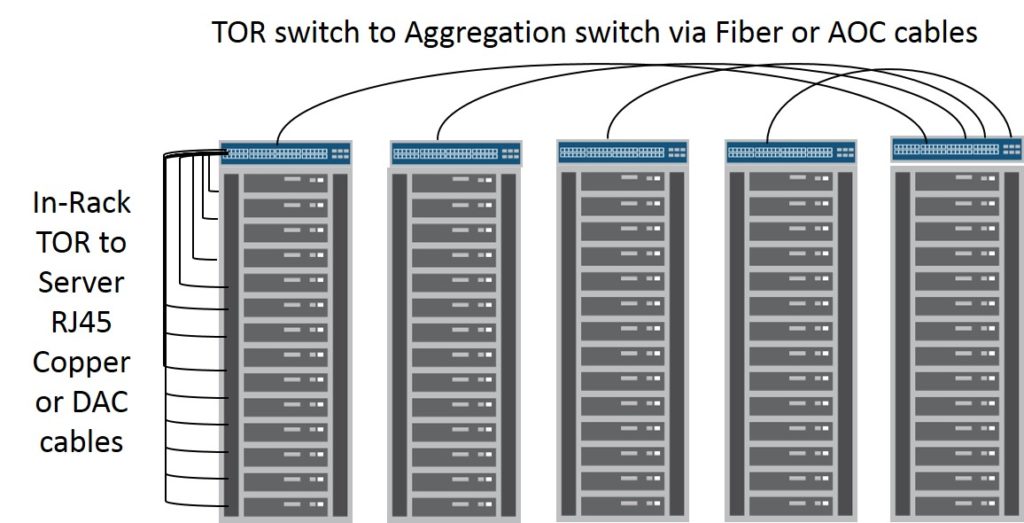
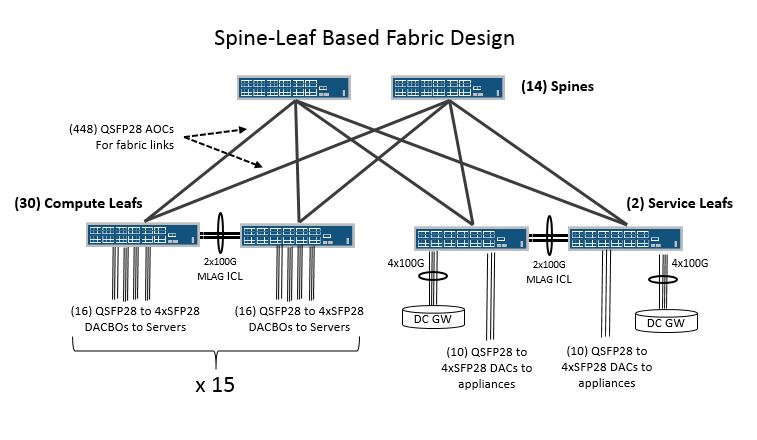
Top-of-rack or TOR model consists of placing a switch within the same rack as the devices which are connecting to it. The switch might be placed in the top most portion of the rack or in the middle of the rack with 1/2 the servers above it and the other 1/2 below it. In this case its common to see either RJ45 copper or DAC cables use to connect in-rack devices to the switch due to the very short intra-rack cabling distance requirement. This short intra-rack wiring scheme also obviates the need for additional space and cost of patch panels for the rack. The only connections that leave the rack should be uplinks from the TOR switch to middle-of-row or end-of-row spine or aggregation switches which typically would be fiber or even AOC based. From a maintenance or failure domain perspective we are dealing with isolation to the rack level so only devices within the rack will be impacted.
Due to the high front panel density counts on 1RU switches deploying a pair of switches in each rack for redundant server connectivity potentially strands a lot of excess ports on each switch. For example if you have a desire to multi-home your servers to a pair of 48-port switches, yet only have 24 servers per rack you could x-connect your servers to another 48-port TOR switch in an adjacent rack. While this reduces the total number of switches and leaves no unused ports it makes for slightly more cumbersome x-rack cabling.
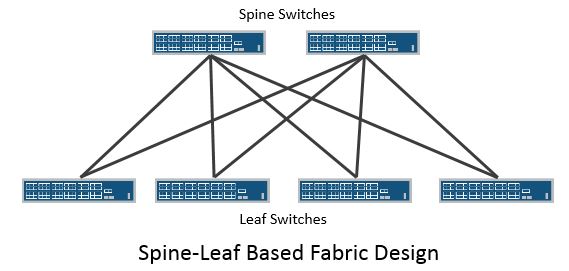
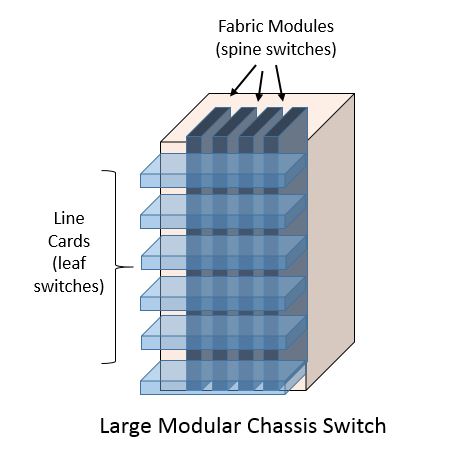
Middle-of-Row or End-of-Row Designs
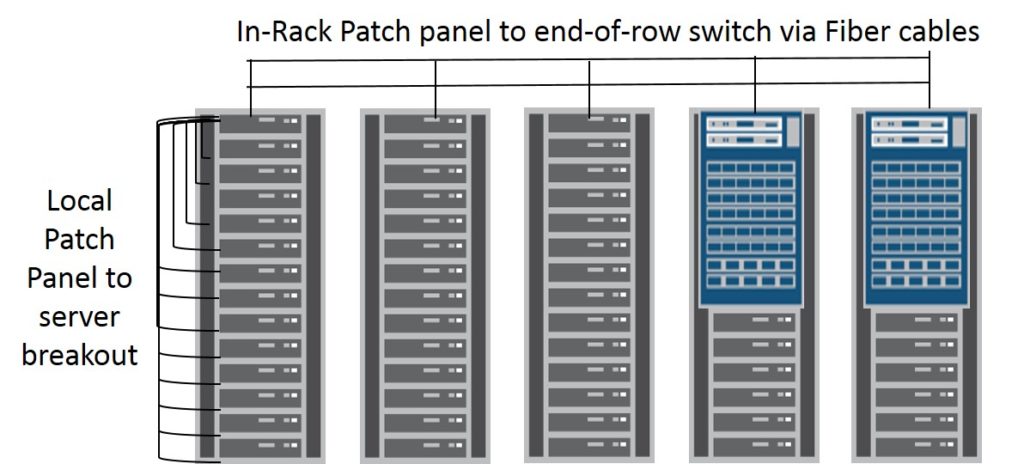
Middle-of-row and End-of-row designs typically consist of a pair of large chassis based switches that aggregate the server connections from all of the racks/cabinets that are in the row. In this model there is no switching device within the rack itself. The connections between the large chassis based switches and each rack would typically be fiber runs that terminate onto in-rack patch panels. From the patch panel individual patch cables would be run to each server in the rack. It is technically possible to run cables the full length of the distance between the middle-of-row or end-of-row chassis based switch pair, however when a cable fault occurs the entire length of the run needs to be replaced which could be cumbersome to deal with.
From a maintenance or failure domain perspective we are dealing with the potential to impact multiple racks in the event of a large chassis based switch failure.
Lets conclude by putting it all together with a table that illustrates how the various form factor, transceiver, connector and cable types combine to offer choices in the placement of the end devices connected to Data Center switches.
Commonly used 10/25/40/100G Data Center Connectivity Options
| Media |
Form Factor |
Cabling and ConnectorType |
Max Distance |
Type of connection |
| 10GBase-T (Copper) |
SFP+ |
CAT6/CAT7 |
100m |
server/appliance within the same rack (10G TOR switch) |
| 10G-USR (Fiber) |
SFP+ |
duplex MMF w/LC connector |
100m |
server/appliance within the same rack (10G TOR switch) |
| 10GBase-SR (Fiber) |
SFP+ |
duplex MMF w/LC connector |
400m |
server/appliance within the same rack (10G TOR switch) or to chassis based switch in end of row (EOR) |
| 10GBase-LR (Fiber) |
SFP+ |
duplex SMF w/LC connector |
10km |
device is cross-DC, between floors, external to DC/DCI |
|
SFP+ |
Direct Attach Copper |
1 to 5m |
server/appliance within the same rack (10G TOR switch) |
|
SFP+ |
Active Optical Cable |
5 to 30m |
server/appliance within the same rack (10G TOR switch) or to chassis based switch in end of row (EOR) |
|
|
|
|
|
| 25GBase-SR |
SFP28 |
duplex MMF w/LC connector |
100m |
server/appliance within the same rack (25G TOR switch) |
|
SFP28 |
Direct Attach Copper |
1 to 5m |
server/appliance within the same rack (25G TOR switch) |
|
SFP28 |
Active Optical Cable |
5 to 30m |
server/appliance within the same rack (25G TOR switch) or to 25G chassis based switch in end of row (EOR) |
|
|
|
|
|
| 40GBase-SR4 (Fiber) |
QSFP+ |
12-fiber MMF w/MPO connector |
150m |
server/appliance within the same rack (40G TOR) or to chassis based switch in end of row (EOR) |
| 40Gx10G-ESR4 (Fiber) |
QSFP+ |
12-fiber MMF w/MPO connector |
400m |
server/appliance within the same rack (40G TOR) or to chassis based switch in end of row (EOR) |
| 40GBASE-CR4 |
QSFP+ |
Direct Attach Copper |
1 to 5m |
server/appliance within the same rack or 40G leaf to 40G spine switch |
|
QSFP+ |
Active Optical Cable |
5 to 30m |
40G leaf to 40G spine switch or to 40G chassis based switch in end of row (EOR) |
|
QSFP+ |
QSFP+ to 4xSFP+ DACBO |
1 to 5m |
10G server/appliance within the same rack |
|
QSFP+ |
QSFP+ to 4xSFP+ AOC |
5 to 30m |
10G server/appliance within the same rack (40G TOR) or to chassis based switch in end of row (EOR) |
|
|
|
|
|
| 100GBase-SR4 (Fiber) |
QSFP28 |
12-fiber MMF w/MPO connector |
100m |
server/appliance within the same rack (TOR) |
| 100GBase-LR4 (Fiber) |
QSFP28 |
duplex SMF w/LC connector |
10km |
device is cross-DC, between floors, external to DC/DCI |
| 100GBASE-CR4 |
QSFP28 |
Direct Attach Copper |
1 to 5m |
server/appliance within the same rack, device to device 100G connectivity (100G leaf to 100G spine) |
|
QSFP28 |
Active Optical Cable |
5 to 30m |
device to device 100G connectivity (100G leaf to 100G spine switch) or 100G chassis based switch in end of row (EOR) |
|
QSFP28 |
QSFP28 to 4xSFP28 DACBO |
1 to 5m |
25G server/appliance within the same rack (100G TOR) |
|
QSFP28 |
QSFP28 to 4xSFP28 AOC |
5 to 30m |
25G server/appliance to 100G chassis based switch in end of row |
I hope you found this useful and now have a better understanding of how to use these components to construct a Data Center cabling scheme.
Disclaimer: The views expressed here are my own and do not necessarily reflect the views of my employer Juniper Networks